Tu IA alucina porque no usa RAG: la técnica que el 75% de empresas ya adoptó (y la mayoría de México todavía no)
RAG conecta tu LLM con datos reales en tiempo real, reduce alucinaciones hasta un 30% y puede ahorrarte millones. Te explicamos cómo funciona y por qué México se está quedando atrás.
Agarras ChatGPT, le preguntas algo sobre los reglamentos internos de tu empresa, y el wey te inventa una respuesta con toda la confianza del mundo. Eso no es un bug raro, es el comportamiento predeterminado de cualquier LLM que no tiene acceso a tus datos. Es lo que pasa cuando usas un modelo “pelón”, sin infraestructura de recuperación de información. Y la solución lleva años existiendo: se llama RAG, y el 75% de las empresas enterprise globales ya la están adoptando, mientras la mayoría de negocios mexicanos todavía discuten si “poner IA” significa contratar una cuenta de ChatGPT Plus.
Qué es RAG y por qué tu LLM sin él es medio inútil
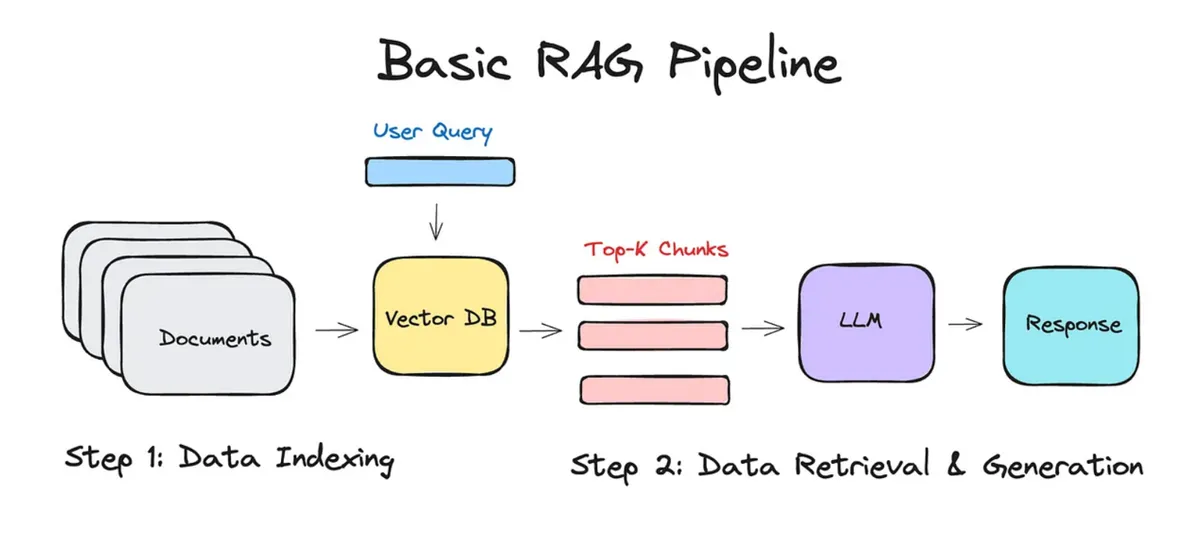
RAG, o Retrieval-Augmented Generation, es una arquitectura que le conecta al modelo de lenguaje una capa de recuperación de información antes de que genere su respuesta. En cristiano: en lugar de que el LLM conteste con lo que “aprendió” hace meses o años, primero va a buscar información relevante a tus bases de datos, documentos o fuentes externas, y con eso arma la respuesta.
El problema del LLM solo es el “conocimiento congelado”. Un modelo entrenado hasta enero de 2025 no sabe nada de lo que pasó después. Y aunque sí sepa sobre el mundo en general, no sabe nada sobre tu empresa, tus clientes, tus políticas internas o los precios que manejas hoy. Sin RAG, el modelo alucina o simplemente dice que no sabe. Con RAG, va, busca, y contesta con datos reales.
MarketsandMarkets proyecta que el mercado RAG llegará a $9,860 millones de dólares para 2030, partiendo de los $1,940 millones que vale hoy. Eso es un CAGR de 38.4% anual, uno de los crecimientos más agresivos en todo el sector de IA.
Las tres capas: RAG básico, híbrido y agéntico
No es un sistema de una sola velocidad. Hay tres niveles de complejidad, y entenderlos te ayuda a saber qué necesitas.
RAG básico: El usuario pregunta, el sistema busca documentos relevantes en un vector database (como Pinecone, Weaviate o ChromaDB), recupera los fragmentos más útiles y los mete al contexto del LLM para que conteste. Simple, efectivo, relativamente barato.
RAG híbrido: Combina búsqueda vectorial (semántica) con búsqueda por palabras clave tradicional (BM25, Elasticsearch). Esto mejora la precisión porque no siempre la búsqueda semántica es mejor que la exacta. Si alguien busca “número de póliza 4857-B”, quieres match exacto, no semántico.
Agentic RAG: El nivel más avanzado. En lugar de una sola consulta y respuesta, hay un agente que puede hacer múltiples búsquedas, refinar sus queries, razonar sobre los resultados y volver a consultar si el primer resultado no fue suficiente. Según el blog de desarrolladores de NVIDIA sobre Agentic RAG, la diferencia clave es que el agente puede “reescribir la query e iterar hasta obtener la mejor respuesta posible”. Esto mejora la precisión en aproximadamente 50% sobre RAG tradicional, pero cuesta más: un pipeline agéntico puede ser hasta 10 veces más caro por consulta.
La tendencia para 2026 es el Adaptive RAG: un clasificador de queries que manda las preguntas simples al pipeline básico (rápido y barato) y las complejas al agéntico (preciso pero costoso). Lo mejor de los dos mundos.
Los números reales que convencen a cualquier CFO
Aquí es donde se pone interesante para quien toma decisiones en una empresa.
LinkedIn implementó RAG combinado con grafos de conocimiento para su equipo de soporte al cliente. El paper publicado en ArXiv documenta los resultados: 77.6% de mejora en recuperación de información (MRR) y reducción del 28.6% en tiempo de resolución por ticket. Seis meses de deployment en producción, no un experimento de laboratorio.
En el sector financiero europeo, un banco implementó RAG para automatizar procesos de conocimiento y reportó ahorros de 20 millones de euros en tres años, con retorno de inversión en apenas dos meses. El sistema liberó el equivalente a 36 empleados de tiempo completo para tareas de mayor valor.
Y en entornos médicos controlados, arquitecturas RAG especializadas han logrado reducir las alucinaciones hasta un 5.8%, lo cual en ese contexto puede ser literalmente la diferencia entre la vida y la muerte.
El 80% de los desarrolladores enterprise consideran que RAG es la forma más efectiva de anclar los LLMs en datos factuales, según datos de adopción del sector.
Como escribimos en nuestra guía para correr IA local con Ollama y LM Studio, la infraestructura de IA ya no es solo para corporaciones, pero RAG sí requiere un nivel de arquitectura que va más allá de instalar un modelo local.
RAG vs Fine-tuning: el debate de costos que importa
La alternativa más común a RAG para personalizar un LLM es el fine-tuning: reentrenar el modelo con tus datos. El problema es el costo y la rigidez.
Un fine-tuning serio de un modelo de buena calidad empieza en $10,000 USD, y eso sin contar el tiempo de preparación de datos ni el mantenimiento. Cuando tus datos cambian, tienes que reentrenar. Es como imprimir un manual de procedimientos en piedra.
RAG, en cambio, solo necesita infraestructura de vector database. Para volúmenes pequeños (hasta 1 millón de vectores), la diferencia de costos entre opciones como Pinecone serverless, Weaviate o soluciones open-source como Qdrant es marginal. La decisión ahí la toma la facilidad operativa, no el precio. Para volúmenes grandes (más de 10 millones de vectores), self-hosted en Kubernetes puede ser 2-3 veces más barato que servicios managed.
La estrategia ganadora en 2026 que están adoptando los equipos más avanzados es combinar ambos: fine-tuning para que el modelo “entienda” el vocabulario y tono de tu industria, más RAG para que tenga acceso a datos actualizados. No es uno o el otro.
México y LATAM: adoptando IA, pero a medias
Aquí está el pedo: LATAM tiene 47% de adopción de IA en empresas, ligeramente por encima del promedio global de 45%, con México con 55% de empresas que planean aumentar inversión en IA. El mercado de IA en México superó los 32,000 millones de pesos en 2025.
Pero la adopción masiva no se está traduciendo en valor real. Computer Weekly lo documenta en su análisis de LATAM: la mayoría de las organizaciones en la región están usando IA de forma superficial, sin la infraestructura que la hace realmente útil. Están pagando por LLMs pelones, conectando ChatGPT a sus procesos sin arquitectura de recuperación, y después se preguntan por qué el modelo “miente”.
El problema no es falta de interés ni de presupuesto. Es falta de conocimiento arquitectónico. La transición de “pilotos de IA” a “IA en producción que funciona” requiere precisamente este tipo de decisiones: implementar RAG, manejar vector databases, diseñar pipelines de recuperación.
96% de organizaciones globales planean expandir IA agéntica en 2026. Para 2026, se espera que 85% de apps enterprise utilicen arquitecturas RAG híbridas. México está en el momento exacto para no quedarse en la primera ola y brincar directamente a implementaciones con arquitectura seria.
Como mencionamos en nuestro análisis de herramientas de IA para programar en 2026, la brecha entre quienes entienden la infraestructura de IA y quienes solo consumen herramientas se está ampliando rápidamente.
Por dónde empezar si quieres implementar RAG
No tienes que hacer un proyecto de seis meses ni contratar un equipo de ML engineers. Los pasos básicos:
- Define tu fuente de datos: documentos internos, base de conocimiento, tickets de soporte, lo que sea que tu LLM necesita para contestar bien.
- Elige tu vector database: para empezar, ChromaDB (open-source, corre local), o Pinecone serverless si quieres managed y no quieres lidiar con infraestructura.
- Indexa tus documentos: los conviertes en embeddings (vectores numéricos) y los guardas.
- Conecta al LLM: frameworks como LangChain o LlamaIndex hacen esto relativamente sencillo. No tienes que construir el pipeline desde cero.
- Evalúa y ajusta: mide la calidad de las respuestas, ajusta el chunking de documentos y los parámetros de recuperación.
Es bastante bacano ver cómo una implementación RAG básica puede transformar completamente la utilidad de un LLM en menos de una semana de trabajo. La curva de aprendizaje existe, pero la relación esfuerzo-resultado está a favor.
La pregunta no es si tu empresa necesita RAG. Si usa datos propios, regulaciones específicas o información que cambia frecuentemente, la respuesta es sí. La pregunta es cuándo lo van a implementar, y si van a llegar antes o después que su competencia.
Fuentes
- MarketsandMarkets: RAG Market worth $9.86 billion by 2030
- NVIDIA Developer Blog: Traditional RAG vs. Agentic RAG
- ArXiv: RAG with Knowledge Graphs for LinkedIn Customer Service
- Computer Weekly: La adopción masiva de IA en LATAM aún no se traduce en valor real
- Techment: RAG in 2026
- RAGAboutIt: Retrieval Augmented Generation in Enterprise AI 2026
- Ecosistema Startup: LATAM adopta IA al 47%
- Kanerika: RAG vs Agentic RAG 2026
Comentarios
No te pierdas ningún post
Recibe lo nuevo de Al Chile Tech directo en tu correo. Sin spam.
También te puede interesar

Visa quiere que tu IA haga tus compras sola: así funciona Intelligent Commerce Connect (y ya probó en México)
Visa lanzó Intelligent Commerce Connect para que agentes de IA compren por ti con tokenización y controles de gasto. Ya hubo un piloto real en México. Te explico cómo funciona y qué viene.

El token es la nueva moneda de la IA: qué es, cuánto cuesta y cómo gastar menos antes de que tu empresa se quede sin presupuesto
El token pasó de ser un concepto técnico a convertirse en el nuevo KPI de las empresas. Precios actuales, por qué el español te cuesta más y cómo reducir tu factura de IA hasta 85%.

Microsoft Copilot se volvió autónomo: las 5 funciones de 2026 Wave 1 que tu empresa debe activar ya
Agent Mode en Office, orquestación multi-agente, integración con Gmail y controles de gasto por equipo: el Wave 1 de Copilot es el mayor salto desde su lanzamiento. Guía práctica para empresas mexicanas.